|
I am a final-year Master's student in Robotics, Systems and Control at ETH Zürich. Currently, I am a Visiting Student Researcher at Stanford University in the Gradient Spaces Lab, advised by Prof. Iro Armeni. During my Master's, I was a research intern at the Microsoft Spatial AI Lab under Prof. Marc Pollefeys, where I focused on spatial video understanding with Vision-Language Models (VLMs). I was also a research assistant at Prof. Konrad Schindler's PRS Lab at ETH, working on diffusion models for dense prediction tasks. Before that, I obtained a Bachelor's in Electrical Engineering from the Technical University of Munich. During this time, I was a research intern at the University of Victoria under Prof. Lin Cai, working on communication networks for autonomous driving, and spent a semester abroad at the University of Edinburgh. |

|
|
|
|
|
|
|
|
|
My research interests lie in computer vision and machine learning, with a focus on 3D scene understanding and generative models. (* denotes equal contribution) |
|
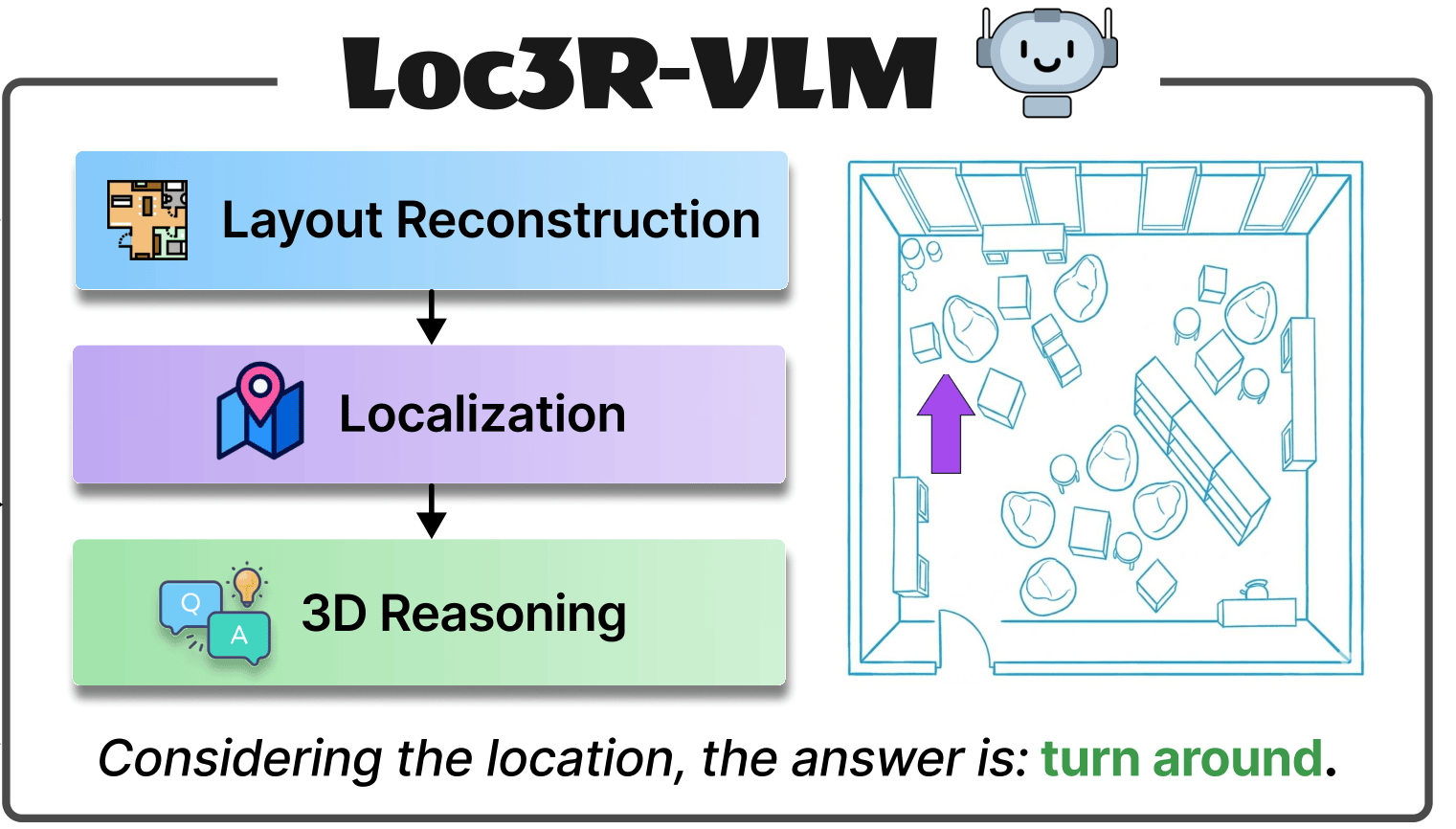
Kevin Qu, Haozhe Qi, Mihai Dusmanu, Mahdi Rad, Rui Wang, Marc Pollefeys arXiv 2026 Paper | Project Page Equipping 2D Vision-Language Models with 3D spatial understanding capabilities. Inspired by human cognition, we guide the model to learn global scene structure and local viewpoint awareness directly from monocular video. |
|
Bingxin Ke*, Kevin Qu*, Tianfu Wang*, Nando Metzger*, Shengyu Huang, Bo Li, Anton Obukhov, Konrad Schindler IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 2025 Paper | Project Page | Code | Demo Repurposing text-to-image diffusion models for a range of dense prediction tasks, including monocular depth estimation, surface normal prediction, and intrinsic image decomposition. |
|
|
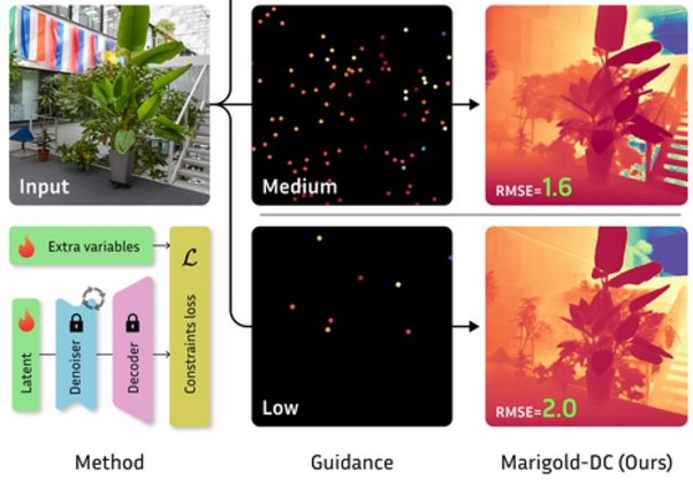
Massimiliano Viola, Kevin Qu, Nando Metzger, Bingxin Ke, Alexander Becker, Konrad Schindler, Anton Obukhov International Conference on Computer Vision (ICCV) 2025 Paper | Project Page | Code | Demo Training-free framework for zero-shot depth completion. We use Marigold as an off-the-shelf monocular depth estimator and guide its diffusion process with sparse depth observations. |
|
Last update March 2026. Thanks for the website template. |